| 数据库系统概念笔记之存储和文件系统及PostgreSQL实现 原作者:张文升 创作时间:2015-12-27 16:09:45+08 |
doudou586 发布于2016-11-18 17:08:05
 评论: 2 评论: 2
 浏览: 28588 浏览: 28588
|
数据库系统概念笔记之存储和文件系统及PostgreSQL实现
作者: 张文升
日期: 2015-12-27
标签: PostgreSQL , RDBMS
数据文件组织
一个数据库被映射到多个不同的文件,这些文件由底层的操作系统来维护。这些文件永久地存在于磁盘上。一个文件在逻辑上组织称为记录的一个序列。这些记录映射到磁盘块上。因为文件由操作系统作为一种基本结构提供,所以我们将假定作为基础的文件系统是存在的。我们需要考虑文件表示逻辑数据模型的不同方式。
块(block)
每个文件分成定长的存储单元,称为块(block)。块是存储分配和数据传输的基本单元。大多数数据库默认使用4~8KB的块大小,但是当创建数据库实例时,许多数据库允许指定块大小。更大的块在一些数据库应用中是很有用的。定长记录和变长记录
在关系数据库中,不同关系的元组通常具有不同的大小。把数据库映射到文件的一种方法是使用多个文件,在任意一个文件中只存储一个固定长度的记录(定长记录),另一种选择是构造自己的文件,使之能够容纳多种长度的记录(变长记录)。
定长记录
定长记录的存储相对变长记录的存储简单。假设记录可以容纳的最大字节数n,一个简单的方法是使用前n个字节来存储第一条记录,记下来的n个字节存储第二条记录,以此类推。但这种简单的方法有两个问题:
除非块的大小正好是n的倍数,否则一些记录会跨过块的边界而存储在另一个块中。于是读写一条这样的记录需要两次块访问;
从这个结构中删除一条记录非常困难。删除的记录所占据的空间必须由文件中的其他记录来填充,或者我们必须用一种方法标记删除的记录,使得该记录可以被忽略。
为了避免第一个问题,可以在一个块中只分配能够容难的最大记录数,余下的字节不再使用。
当一条记录被删除时,可以把紧随其后的记录移动到被删除记录先前占据的空间,以此类推,直到被删记录后面的每一条记录都向前做了移动,这种方法需要移动大量的记录,简单的将文件的最后一条记录移动到被删除记录所占据的空间可能更容易一些,但这样也并不理想,因为这样做需要额外的块访问操作。由于插入操作通常比删除操作更频繁,因此让已经被删除的记录占据的空间空着,一直等到随后进行的插入操作重用这个可用空间就比较合理。仅在被删记录上做一个标记是不够的,因为当插入操作执行时,找到这个可用空间十分困难,因此需要引入额外的结构—-文件头。
文件头包含有关文件的各种信息。现在我们只需要在文件头中存储被删除的第一个记录的地址。在被删除的第一个记录中存放第二个可用记录的地址,以此类推。因为它们指向一个记录的地址,可以直观的把这些存储的地址看作指针。于是,被删除的记录形成了一条链表,通常称为空闲列表(free list)。
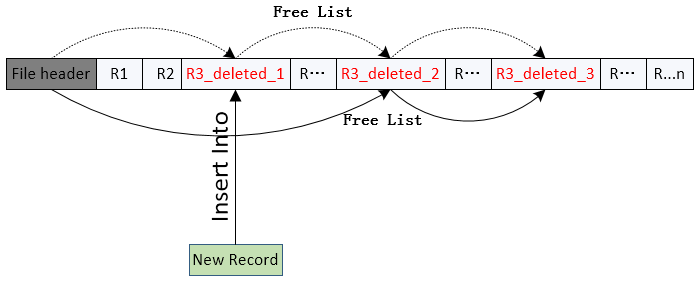
在插入一条新记录时,使用文件头所指向的第一个可用记录作为新插入的这条记录的存储空间,并且将文件头的指针指向下一个可用记录的地址。如果没有可用空间,则把这条新记录添加到文件末尾。
变长记录
实现变长记录的存储需要解决两个不同的问题:
如何描述一条记录,使得单个属性可以轻松抽取;
如何在块中存储变长记录,使得块中的记录可以轻松抽取;
一条变长记录通常分为两部分,初始部分是定长属性,接下来是变长属性。对于定长属性,如数字值,日期或定长字符串,分配存储它们所需的字节数。对于变长属性,在记录的初始部分标识为一个对值(“对”由偏移量,长度构成),其中偏移量标识在记录中该属性的数据开始的位置,长度标识变长属性的字节长度。在记录的初始定长部分之后,这些属性的值是连续存储的。因此无论是定长还是变长,记录初始部分存储有关每个属性固定长度的信息。
例如现在有这样一个记录,它的属性伪代码:
type instructor = record
id varchar(5);
name varchar(20);
dept_name varchar(20);
salary numeric(8,2);
end
它的前三个属性id,name,deptname是变长字符串,第四个属性salary是固定长度,假定偏移量和长度值存储在两个字节中,即每个属性占4个字节。salary属性用8个字节存储,并且每个字符串占用和其拥有字符数一样多的字节数。
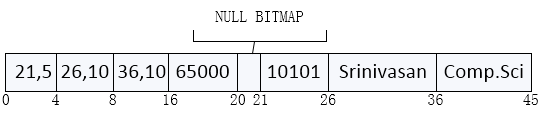
NULL BITMAP用来表示记录的哪个属性是NULL值。
以上描述了变长记录的单条记录的存储形式,在一个块中组织和存储变长记录的集合一般采用分槽的页结构(slotted-page structure)。
每个块的开始处有一个块头,其中包含:
- 记录条目的个数
- 块中空闲空间的末尾处
- 一个包含记录位置和大小组成的数组
记录从块的尾部开始连续排列。块中空闲空间是连续的,空闲空间位于块头数组的最后一个条目和第一条记录之间。如果插入一条记录,在空闲空间的尾部给这条记录分配空间,并且将包含这条记录位置和大小的条目添加到块头用于包含记录位置和大小组成的数组中。
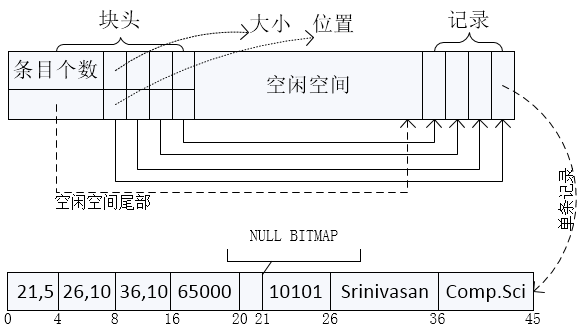
如果一条记录被删除,它所占用的空间被释放,并且它的条目被设置成被删除状态,例如这条记录的大小设为-1。此外,块中在被删除记录之前的记录将被移动,使得由删除而产生的空闲空间得以重用,并且所有空闲空间仍然存在于块头与第一条记录之间。块头中的空闲空间末尾指针也做适当修改。移动记录的代价并不高,因为块的大小是有限制的,典型的值为4~8KB。
在PostgreSQL中的实现
在PostgreSQL中,每个表都用一个文件存储,表文件以表的OID命名。对于大小超出1G的表数据文件,PG会自动将其切分为多个文件来存储,切分出的文件用OID.<顺序号>来命名。例如下面这张12GB大的表的数据文件:
SELECT pg_size_pretty(pg_relation_size('tbl')); -- 表tbl有12GB
SELECT oid FROM pg_database WHERE datname = 'mydb'; -- 数据库mydb的OID为:18473
SELECT relfilenode FROM pg_class WHERE relname = 'tbl'; --表tbl的OID为:653372
查看这张表的数据文件:
[postgres@pgsql ~]$ ll /data/base/18473/ -h | grep '653372' -rw------- 1 postgres postgres 1.0G Nov 27 16:37 653372 -rw------- 1 postgres postgres 1.0G Nov 27 16:25 653372.1 ...... -rw------- 1 postgres postgres 1.0G Nov 27 16:23 653372.10 ...... -rw------- 1 postgres postgres 866M Nov 27 15:12 653372.11 -rw------- 1 postgres postgres 3.0M Nov 27 16:40 653372_fsm -rw------- 1 postgres postgres 192K Nov 27 16:40 653372_vm
其中后缀为_fsm和_vm这两个表文件的附属文件是空间空闲映射表文件和可见性映射表文件。每个表文件由多个BLCKSZ字节大小的page组成,文件的写入是以page为最小单位。在PostgreSQL中,每个page缺省大小为8K,可以在编译PostgreSQL时指定BLCKSZ的大小,对于IO性能较好的硬件,增加BLCKSZ的大小可以显著提升数据库性能。每个page又可以包含多个tuple(在PG中将保存在磁盘中的块称为page,而将内存中的块称为buffer,行称为tuple,这些都是与数学概念相同的)。
在PostgreSQL中,表文件中的tuple之间不进行关联,这样的表文件称为堆文件,每个堆文件都是由多个page组成,它在物理存储中的存储形式如下图所示:
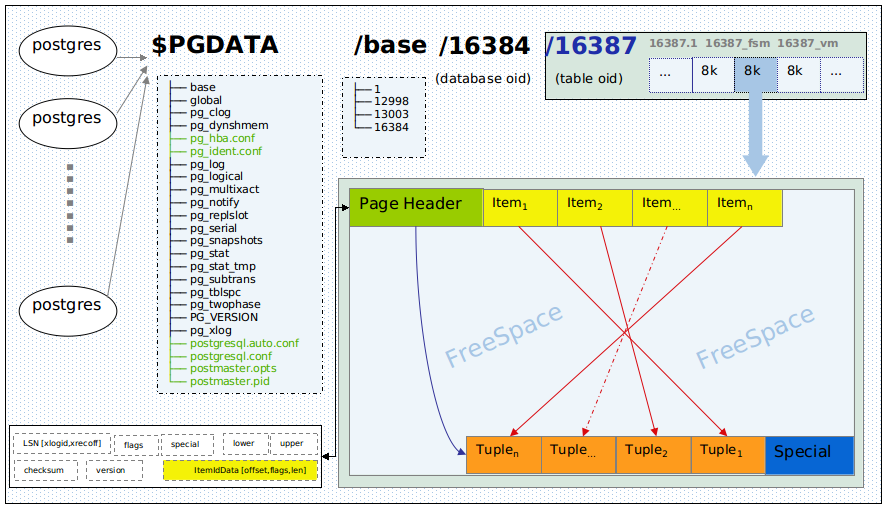
PageHeaderData结构描述了一个数据页的页头信息,它包含页的一些元信息。 它的结构及其结构指针PageHeader的定义如下:
typedef struct PageHeaderData
{
/* XXX LSN is member of *any* block, not only page-organized ones */
PageXLogRecPtr pd_lsn; /* LSN: next byte after last byte of xlog
* record for last change to this page */
uint16 pd_checksum; /* checksum */
uint16 pd_flags; /* flag bits, see below */
LocationIndex pd_lower; /* offset to start of free space */
LocationIndex pd_upper; /* offset to end of free space */
LocationIndex pd_special; /* offset to start of special space */
uint16 pd_pagesize_version;
TransactionId pd_prune_xid; /* oldest prunable XID, or zero if none */
ItemIdData pd_linp[1]; /* beginning of line pointer array */
} PageHeaderData;
typedef PageHeaderData *PageHeader;
pd_lsn:在ARIES Recovery Algorithm的解释中,这个lsn被称为PageLSN,它确定和记录了最后更改此页的xlog记录的LSN,把数据页和WAL日志关联,用于恢复数据时校验日志文件和数据文件的一致性; 它的结构为:
typedef struct
{
uint32 xlogid; /* high bits */
uint32 xrecoff; /* low bits */
} PageXLogRecPtr;
pd_lsn的高位为xlogid,低位记录偏移量;因为历史原因,64bit的LSN保存为两个32bit的值。 pg_flags:标识页面的数据存储情况,它可以有以下的值:
/* Bufpage.h line:164 */
#define PD_HAS_FREE_LINES 0x0001 /* are there any unused line pointers? */
#define PD_PAGE_FULL 0x0002 /* not enough free space for new
* tuple? */
#define PD_ALL_VISIBLE 0x0004 /* all tuples on page are visible to
* everyone */
#define PD_VALID_FLAG_BITS 0x0007 /* OR of all valid pd_flags bits */
pd_lower:指向空闲空间的起始位置;
pd_upper:指向空闲空间的结束位置;
pd_special : 指向special space的开始位置,该项在数据文件中是空的,主要是针对不同索引,在索引篇再详细分解它
pd_checksum :
pd_pagesize_version :不同的PostgreSQL版本的页的格式可能会不同。(详细说明见Bufpage.h line:184)
pd_linp[1] : 行指针数组,就是上图中的Item1.Item2….Item…,这些地址指向Tuple的存储位置。
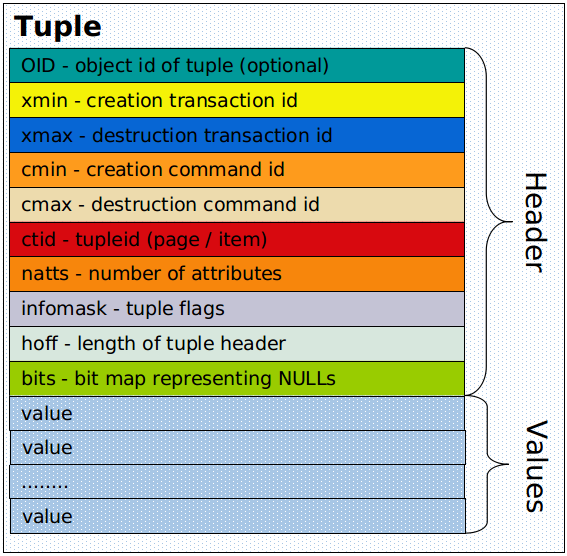
每一个Tuple的结构如下:
每个tuple包含两部分的内容,一部分为HeapTupleHeaderData,用来保存tuple的元信息,如上图所示,包含该tuple的OID、xmin、cmin等,另一部分为HeapTupleData,用来保存tuple的数据。
HeapTupleHeaderData及其结构指针的定义如下:
typedef struct HeapTupleFields
{
TransactionId t_xmin; /* inserting xact ID */
TransactionId t_xmax; /* deleting or locking xact ID */
union
{
CommandId t_cid; /* inserting or deleting command ID, or both */
TransactionId t_xvac; /* old-style VACUUM FULL xact ID */
} t_field3;
} HeapTupleFields;
typedef struct DatumTupleFields
{
int32 datum_len_; /* varlena header (do not touch directly!) */
int32 datum_typmod; /* -1, or identifier of a record type */
Oid datum_typeid; /* composite type OID, or RECORDOID */
/*
* Note: field ordering is chosen with thought that Oid might someday
* widen to 64 bits.
*/
} DatumTupleFields;
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* current TID of this or newer tuple */
/* Fields below here must match MinimalTupleData! */
uint16 t_infomask2; /* number of attributes + various flags */
uint16 t_infomask; /* various flag bits, see below */
uint8 t_hoff; /* sizeof header incl. bitmap, padding */
/* ^ - 23 bytes - ^ */
bits8 t_bits[1]; /* bitmap of NULLs -- VARIABLE LENGTH */
/* MORE DATA FOLLOWS AT END OF STRUCT */
};
typedef HeapTupleHeaderData *HeapTupleHeader;
参考文档
- 《PostgreSQL数据库内核分析(彭智勇 彭煜伟)》
- 《数据库系统概念》
- Architecture of a Database System
- http://db.cs.berkeley.edu/papers/fntdb07-architecture.pdf
- 数据库系统体系结构:第6章 事务:并发控制和恢复
- http://dblab.xmu.edu.cn/post/1359/
请在登录后发表评论,否则无法保存。
