| PostgreSQL 9.6 引领开源数据库攻克多核并行计算难题(第二部分) 原作者:digoal / 德哥 创作时间:2016-10-06 00:20:29+08 |
doudou586 发布于2016-10-06 00:20:29
 评论: 4 评论: 4
 浏览: 10951 浏览: 10951
|

五、测试2 (数据量小于sharedbuffer)
创建一张测试表,包含一个比特位字段,后面用于测试。
postgres=# create unlogged table t_bit1 (id bit(200))with (autovacuum_enabled=off, parallel_workers=128); CREATE TABLE
并行插入10亿记录
for ((i=1;i<=50;i++)) ; do psql -c "insert intot_bit1 selectB'1010101010101010101010101010101010101010101010101010101010101010101010101010 101010101010101010101010101010101010101010101010101010101010101010101010101010101010 1010101010101010101010101010101010101010'from generate_series(1,20000000);" & done
单表10亿,56GB
postgres=# \dt+
List of relations
Schema | Name | Type | Owner | Size |Description
--------+--------+-------+----------+--------+-------------
public | t_bit1 |table | postgres | 56 GB |
聚合测试
非并行模式
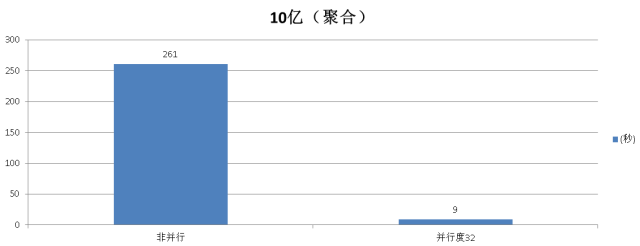
postgres=# set force_parallel_mode =off; postgres=# set max_parallel_workers_per_gather = 0; postgres=# select count(*) from t_bit1 where bitand(id,'1010101010101010101010101010 101010101010101010101010101010101010101010101010101010101010101010101010101010101010 101010101010101010101010101010101010101010101010101010101010101010101010101010101010 1010')=B'101010101010101010101010101010101010101010101010101010101010101010101010101 010101010101010101010101010101010101010101010101010101010101010101010101010101010101 01010101010101010101010101010101010101011'; Time: 261679.060 ms
并行模式
postgres=# set force_parallel_mode = on; postgres=# set max_parallel_workers_per_gather = 32; postgres=# select count(*) from t_bit1 where bitand(id, '1010101010101010101010101010 1010101010101010101010101010101010101010101010101010101010101010101010101010101010101 0101010101010101010101010101010101010101010101010101010101010101010101010101010101010 10')=B'101010101010101010101010101010101010101010101010101010101010101010101010101010 1010101010101010101010101010101010101010101010101010101010101010101010101010101010101 0101010101010101010101010101010101011'; Time: 9704.983 ms
hash JOIN测试
1亿 JOIN 5000万
create unlogged table t1(id int, info text) with (autovacuum_enabled=off,parallel_workers=128); create unlogged table t2(id int, info text) with(autovacuum_enabled=off, parallel_workers=128); insert into t1 select generate_series(1,100000000); insert into t2 select generate_series(1,50000000);
非并行模式
postgres=# set force_parallel_mode =off;
postgres=# set max_parallel_workers_per_gather = 0;
postgres=# set enable_merjoin=off;
postgres=# explain verbose select count(*) from t1 joint2 using(id);
QUERY PLAN
---------------------------------------------------------------------------------------
Aggregate (cost=296050602904.73..296050602904.74 rows=1 width=8)
Output: count(*)
-> Hash Join (cost=963185.44..276314071764.57 rows=7894612456066width=0)
Hash Cond: (t1.id = t2.id)
-> Seq Scan on public.t1 (cost=0.00..1004425.06rows=56194706 width=4)
Output: t1.id
-> Hash (cost=502212.53..502212.53 rows=28097353width=4)
Output: t2.id
-> Seq Scan on public.t2 (cost=0.00..502212.53 rows=28097353 width=4)
Output: t2.id
(10 rows)
postgres=# select count(*) from t1 join t2 using(id);
count
----------
50000000
(1 row)
Time: 60630.148 ms
并行模式
postgres=# set force_parallel_mode = on;
postgres=# set max_parallel_workers_per_gather = 32;
postgres=# explain verbose select count(*) from t1 joint2 using(id);
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=28372817100.45..28372817100.46 rows=1 width=8)
Output:count(*)
-> Gather (cost=28372817097.16..28372817100.37 rows=32 width=8)
Output: (PARTIAL count(*))
Workers Planned: 32
-> Partial Aggregate (cost=28372816097.16..28372816097.17 rows=1 width=8)
Output: PARTIAL count(*)
-> Hash Join (cost=963185.44..8636284956.99 rows=7894612456066 width=0)
Hash Cond: (t1.id =t2.id)
-> ParallelSeq Scan on public.t1 (cost=0.00..460038.85 rows=1756085 width=4)
Output: t1.id
-> Hash (cost=502212.53..502212.53 rows=28097353 width=4)
Output: t2.id
-> Seq Scan on public.t2 (cost=0.00..502212.53 rows=28097353width=4)
Output: t2.id
(15 rows)
select count(*) from t1 join t2 using(id);
Execution time:50958.985 ms
postgres=# set max_parallel_workers_per_gather = 4;
select count(*) from t1 join t2 using(id);
Time: 39386.647 ms
建议JOIN不要设置太大的并行度。
六、如何设置并行度以及源码分析
GUC变量
1. 控制整个数据库集群同时能开启多少个work process,必须设置。
max_worker_processes = 128 # (change requires restart)
2. 控制一个并行的EXEC NODE最多能开启多少个并行处理单元,同时还需要参考表级参数parallel_workers,或者PG内核内置的算法,根据表的大小计算需要开启多少和并行处理单元。实际取小的。
max_parallel_workers_per_gather = 16 # takenfrom max_worker_processes
如果同时还设置了表的并行度parallel_workers,则最终并行度取min(max_parallel_degree, parallel_degree )
/*
* Use the table parallel_degree, butdon't go further than
* max_parallel_degree.
*/
parallel_degree =Min(rel->rel_parallel_degree, max_parallel_degree);
如果表没有设置并行度parallel_workers ,则根据表的大小 和parallel_threshold 这个硬编码值决定,计算得出(见函数create_plain_partial_paths)
依旧受到max_parallel_workers_per_gather 参数的限制,不能大于它,取小的,前面已经交代了。
代码如下(release后可能有些许修改)
src/backend/optimizer/util/plancat.c
void get_relation_info(PlannerInfo *root, OidrelationObjectId, bool inhparent,RelOptInfo *rel)
{
...
/* Retrive the parallel_degree reloption, if set. */
rel->rel_parallel_degree = RelationGetParallelDegree(relation,-1);
...
src/include/utils/rel.h
/*
*RelationGetParallelDegree
* Returns the relation's parallel_degree. Note multiple eval of argument!
*/
#define RelationGetParallelDegree(relation, defaultpd) \
((relation)->rd_options ? \
((StdRdOptions *) (relation)->rd_options)->parallel_degree: (defaultpd))
src/backend/optimizer/path/allpaths.c
/*
*create_plain_partial_paths
* Build partial access paths for parallel scan of a plain relation
*/
static void create_plain_partial_paths(PlannerInfo *root, RelOptInfo*rel)
{
int parallel_degree = 1;
/*
* If the user has set the parallel_degree reloption, we decidewhat to do
* based on the value of that option. Otherwise, we estimatea value.
*/
if (rel->rel_parallel_degree != -1)
{
/*
* If parallel_degree = 0 is set forthis relation, bail out. The
* user does not want a parallel pathfor this relation.
*/
if (rel->rel_parallel_degree == 0)
return;
/*
* Use the table parallel_degree, butdon't go further than
* max_parallel_degree.
*/
parallel_degree =Min(rel->rel_parallel_degree, max_parallel_degree);
}
else
{
int parallel_threshold = 1000;
/*
* If this relation is too small to beworth a parallel scan, just
* return without doing anything ...unless it's an inheritance child.
* In that case, we want to generate aparallel path here anyway. It
* might not be worthwhile just forthis relation, but when combined
* with all of its inheritancesiblings it may well pay off.
*/
if (rel->pages reloptkind == RELOPT_BASEREL)
return;
// 表级并行度没有设置时,通过表的大小和parallel_threshold 计算并行度
/*
* Limit the degree of parallelismlogarithmically based on the size
* of the relation. Thisprobably needs to be a good deal more
* sophisticated, but we need somethinghere for now.
*/
while (rel->pages >parallel_threshold * 3 &&
parallel_degree < max_parallel_degree)
{
parallel_degree++;
parallel_threshold*= 3;
if(parallel_threshold >= PG_INT32_MAX / 3)
break;
}
}
/* Add an unordered partial path based on a parallel sequentialscan. */
add_partial_path(rel, create_seqscan_path(root, rel, NULL,parallel_degree));
}
3. 计算并行处理的成本,如果成本高于非并行,则不会开启并行处理。
#parallel_tuple_cost = 0.1 # same scale as above #parallel_setup_cost = 1000.0 # same scale asabove
4. 小于这个值的表,不会开启并行。
#min_parallel_relation_size = 8MB
5. 告诉优化器,强制开启并行。
#force_parallel_mode = off
表级参数
6. 不通过表的大小计算并行度,而是直接告诉优化器这个表需要开启多少个并行计算单元。
parallel_workers (integer) This sets the number of workers that should be used toassist a parallel scan of this table. If not set, the system will determine a value based onthe relation size. The actual number of workers chosen by the planner may beless, for example due to the setting of max_worker_processes.
七、参考信息
- http://www.postgresql.org/docs/9.6/static/sql-createtable.html
- http://www.postgresql.org/docs/9.6/static/runtime-config-query.html#RUNTIME-CONFIG-QUERY-OTHER
- http://www.postgresql.org/docs/9.6/static/runtime-config-resource.html#RUNTIME-CONFIG-RESOURCE-ASYNC-BEHAVIOR
- http://www.postgresql.org/docs/9.6/static/runtime-config-query.html#RUNTIME-CONFIG-QUERY-CONSTANTS
Postgres大象会2016官方报名通道:http://www.huodongxing.com/event/8352217821400
扫描报名

请在登录后发表评论,否则无法保存。
1# __
xcvxcvsdf 回答于 2025-01-16 07:56:45+08
https://su.tiancebbs.cn/hjzl/468149.html
https://gbai.tiancebbs.cn/mayi-store.xml
https://aihuishou.tiancebbs.cn/hpzzss/mayi-info.xml
https://changshushi.tiancebbs.cn/hjzl/464120.html
https://cd.tiancebbs.cn/news/39415.html
https://zulin.tiancebbs.cn/sh/5803.html
https://xisi.tiancebbs.cn/mayi-store.xml
https://gling.tiancebbs.cn/zhuanyejinenkecheng/54591.html
https://mjqzhoubian.tiancebbs.cn/mayi-info.xml
https://zulin.tiancebbs.cn/sh/2283.html
https://aihuishou.tiancebbs.cn/sh/5019.html
https://aihuishou.tiancebbs.cn/baotingxian/mayi-info.xml
https://www.tiancebbs.cn/ershoufang/504360.html
https://tiexi.tiancebbs.cn/mayi-store.xml
https://kuixin.tiancebbs.cn/
https://cd.tiancebbs.cn/news/44099.html
https://www.tiancebbs.cn/ershoufang/502612.html
2# __
xcvxcvsdf 回答于 2024-10-29 18:53:21+08
http://js.sytcxxw.cn/leshan/
https://dychengxi.tiancebbs.cn/
http://nalei.zjtcbmw.cn/cqxs/
http://yz.cqtcxxw.cn/td/
https://yanji.tiancebbs.cn/
https://fenlei.tiancebbs.cn/kfjz/
http://gx.lztcxxw.cn/zhangzhou/
http://ruanwen.xztcxxw.cn/neijiang/
http://bjtcxxw.cn/qcyp/
http://ly.shtcxxw.cn/putian/
http://fuyang.tjtcbmw.cn/jinshanqu/
https://fenlei.tiancebbs.cn/quanzhou/
http://js.sytcxxw.cn/bjjz/
https://dywchanyeyuan.tiancebbs.cn/
https://jiangchuanzhen.tiancebbs.cn/
https://fenlei.tiancebbs.cn/hbzjk/
http://ruanwen.xztcxxw.cn/ahhs/
3# __
xcvxcvsdf 回答于 2024-10-16 09:25:55+08
https://zulin.tiancebbs.cn/sh/240.html
https://taicang.tiancebbs.cn/hjzl/462651.html
https://zulin.tiancebbs.cn/sh/992.html
https://lc.tiancebbs.cn/qths/474374.html
https://xinfeng.tiancebbs.cn/qths/463319.html
https://sl.tiancebbs.cn/qths/469838.html
https://www.tiancebbs.cn/ershoufang/470406.html
https://su.tiancebbs.cn/hjzl/468248.html
https://www.tiancebbs.cn/ershouwang/473396.html
https://zulin.tiancebbs.cn/sh/3497.html
https://aihuishou.tiancebbs.cn/sh/1178.html
https://su.tiancebbs.cn/hjzl/471209.html
https://zulin.tiancebbs.cn/sh/15.html
https://sz.tiancebbs.cn/qtzypx/415336.html
https://zulin.tiancebbs.cn/sh/382.html
https://gz.tiancebbs.cn/b2bdgdq/56197.html
https://www.tiancebbs.cn/hgylhs/164396.html
4# __
xiaowu 回答于 2024-04-21 08:29:01+08
个性符号网名:https://www.nanss.com/mingcheng/1237.html yy频道名字:https://www.nanss.com/mingcheng/1226.html 关于七夕的唯美句子:https://www.nanss.com/yulu/1295.html 女生英文名:https://www.nanss.com/mingcheng/827.html 网名女霸气:https://www.nanss.com/mingcheng/646.html 实习总结3000字:https://www.nanss.com/gongzuo/704.html 一句话凉透人心的句子:https://www.nanss.com/yulu/1047.html 实习感受:https://www.nanss.com/xuexi/543.html 独一无二仙气十足的网名:https://www.nanss.com/mingcheng/788.html 个人简介范文:https://www.nanss.com/gongzuo/761.html 美术教学反思:https://www.nanss.com/gongzuo/968.html 失望的句子:https://www.nanss.com/yulu/1108.html 生态学实习报告:https://www.nanss.com/xuexi/1149.html 好看网名大全:https://www.nanss.com/mingcheng/989.html 古风女名:https://www.nanss.com/mingcheng/803.html 最简单的网名:https://www.nanss.com/mingcheng/1435.html 情侣名称:https://www.nanss.com/mingcheng/696.html 高端上档次的群聊名:https://www.nanss.com/mingcheng/1335.html 与世无争的网名:https://www.nanss.com/mingcheng/1422.html 简单网名女生:https://www.nanss.com/mingcheng/1414.html 最吸引人的抖音名字:https://www.nanss.com/mingcheng/1477.html 七个字的网名:https://www.nanss.com/mingcheng/1191.html 盼望作文:https://www.nanss.com/xuexi/807.html 游戏家族名字:https://www.nanss.com/mingcheng/1244.html 脑筋里转弯大全:https://www.nanss.com/shenghuo/750.html 四字网名:https://www.nanss.com/mingcheng/832.html 积极面对生活的句子:https://www.nanss.com/yulu/1076.html 讽刺爱情的经典句子:https://www.nanss.com/yulu/1071.html 昵称女:https://www.nanss.com/mingcheng/902.html 吃鸡又菜又皮的名字:https://www.nanss.com/mingcheng/713.html
