| 【转】:从Postgres95到PostgreSQL9.5:新版亮眼特性 原作者:萧少聪 创作时间:2016-01-14 10:10:31+08 |
doudou586 发布于2016-01-20 10:10:31
 评论: 7 评论: 7
 浏览: 14955 浏览: 14955
|
编者按:高可用架构分享及传播在架构领域具有典型意义的文章,本文由萧少聪分享。转载请注明来自高可用架构公众号「ArchNotes」。
萧少聪(花名:铁庵),广东中山人,阿里云 RDS for PostgreSQL/PPAS 云数据库产品经理。 2011 年开始与李元佳等组建 Postgres 中国用户会,现任用户会主席。 自 2007 年起支持中国 Postgres 数据库发展,多年来,在中国及台湾地区协助众多企业成功从 MySQL,Oracle 等数据库转型使用 Postgres 系列数据库。
 |
“在 PostgreSQL 中使用 JSON 除了可以更好地处理移动互联网数据外,对于传统业务的由于业务形态可能随时变化,而导致数据库中“宽表”设计也有很大的帮助。” —— 萧少聪 |
Postgres95 介绍
现在被称为 PostgreSQL 的对象-关系型数据库管理系统(有一段时间被称为 Postgres95)是从伯克利写的 POSTGRES 软件包发展而来的。PostgreSQL 被誉为是世界上可以获得的最先进的开放源码的数据库系统, 支持几乎所有 SQL 语法(包括子查询,事务和用户定义类型和函数)。提供多版本并行控制, 并且支持多程开发语言,包括 Java、.Net、PHP、C、C++、node.js、perl、tcl 和 Python 等。
PostgreSQL 原于 Ingres,由 2014 年图灵奖得主 Michael Stonebraker 主导开发。早在 1970 年代前期,Michael Stonebraker 就在 Edgar Codd 的关系数据库论文启发下,组织伯克利的师生,开始开发最早的两个关系数据库之一 Ingres(另一个是 IBM System R)。
Ingres 的基础上后来发展出 Sybase 和 SQL Server 两大主流数据库。Ingres 在关系数据库的查询语言设计、查询处理、存取方法、并发控制和查询重写等技术上都有重大贡献。
1980 年代他又开发了 POSTGRES 项目,目的是在关系数据库之上增加对更复杂的数据类型的支持,包括对象、地理数据、时间序列数据等。后来这个系统演变为开源的 PostgreSQL,Greenplum、Aster Data、Netezza 和 Stonebraker自己创办的 Ilustra(后被Informix收购)等多个商业公司和开源的产品都是基于 PostgreSQL 开发的。
在 1994 年,Andrew Yu 和 Jolly Chen 两位华人 向 POSTGRES 中增加了 SQL 语言的解释器,命名为 Postgres95,后重新命名为 PostgreSQL。
PostgresSQL 版本发展历史
1997 年,正式改名为 PostgreSQL 6.x,主要功能发展:unique indexes、Multi-column indexes、sequences、money data type (当前美国多家银行使用)、GEQO (GEnetic Query Optimizer 基因查询优化算法)、支持 JDBC、支持触发器、支持存储过程语言 PL/pgSQL、支持视图、实现 MVCC 多版本控制、临时表
我们可以年到在上世纪 90 年代,PostgreSQL 已经有十分完善的现代关系型数据库功能。反观 MySQL,到 2005 年才比较完善地提供以上功能,当然,也由于借助 LAMP 架构 MySQL 成为了开源数据库占有率第一的数据库。但在很多核心系统中,PostgreSQL 上世纪 90 年代到 20 世纪初企业级,甚至军方核心系统中几乎唯一使用的开源数据库。比较重点的系统包括:NASA、美国海空军、银行等。
2000年,PostgreSQL 7.x,主要功能发展:对 Foreign keys 外键的支持、支持多表 JOIN、实现 WAL 日志系统(类似 redo log)、Outer JOINS、支持国际化语言、支持用户 Schema 隔离。这一版本主要对数据库功能进行增强,主要表现在对多表处理,及容错性方面。
2005年,PostgreSQL 8.x,主要功能发展:支持 Windows 平台、Savepoints、表空间管理、基于任意时间点的恢复、2 阶段提交、表分区、全文检索、XML、窗口函数、递归查询。
是的,您没有看错,2005年PostgreSQL才支持Windows平台!!所以大家不要再问题我为什么PostgreSQL被我说得特备NB,但在中国没有火。都想想自己10年前在用什么系统吧!
2010 年,PostgreSQL 9.x,这是一个让中国用户直正了解并使用 PostgreSQL 的开始。而实际上,同年 Uber、Instagram、Skype 等国外知名互联网公司大量使用 PostgreSQL,特别是 Uber 通过 PostGIS 的地理信息功能,在后续几年中横扫了 O2O 打车市场。
PostgreSQL 9.0:支持64位Windows系统、异步流数据复制、Hot Standby(相当于Active DataGuard)。
PostgreSQL 9.1:支持同步数据复制、unlogged tabels、serializable snapshot isolation、FDW 外部表。
此版本后,PostgreSQL 开始得到中国多个行业用户的关注,开始有应用于电信、保险、制造业等边缘系统。
PostgreSQL 9.2:级联数据复制、index-only scans、JSON 数据类型、空间分区 GiST 索引(SP-GiST)
PostgreSQL 9.3:数据校对 checksums、丰富 JSON 函数及操作符、并行 pg_dump 备份、物化视图。
PostgreSQL 9.4:JSONB 数据类型(高性能可索引)、可在线刷新物化视图、支持Linux大页操作、支持数据预热
经过 9.x 版本多年的持续更新,我们可以看到,PostgreSQL 在企业功能上已经与商业数据库没有太大差距。同时 JSON 的加入,为很多传统企业抹平了进入移动互联网业务的道路,同时在很多特殊场景下无需再通过“宽表”进行数据处理。物化视图、Linux 大页面操作、数据预热等功能为进一步实现 OLAP 功能奠定了基础。
PostgresSQL 9.5 的亮眼特性
UPSERT
INSERT ... ON CONFLICT, also known as “UPSERT”
如果你有用过 Oracle 的 Megre 功能,我相信不用我多说你都知道这是有多么的方便。以下是一些 DEMO:
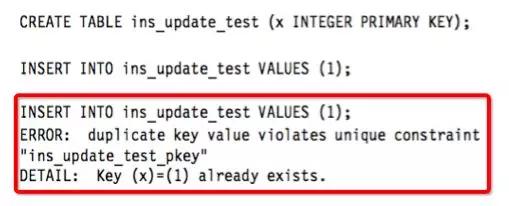
可以看到由于x是主键因此数第 2 次 INSER INTO 无法插入成功。我们再看:

可以看到 INSERT 失败后,进行 UPDATE。我们可以将例子写得更加复杂一些:

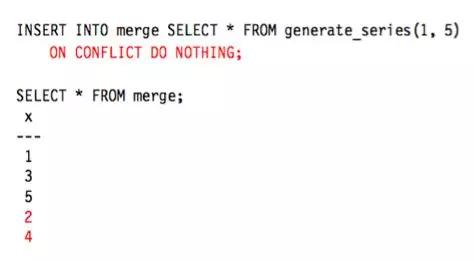
以上 generate_eries(1,5) 在 PostgreSQL 的意思是生成 1 到 5 的序列,由于1、3、5 数据已经存在,因此无法写入。而通过以下方式即可写入数据

还想做更深入的操作?我们再看一个

以上例子我们可以方便地实现数据库中对于错误中已存在数据的灵活处理,在复杂业务场景十分实用。
如:在进行 SQL 语句编写时,我们经常会遇到大量的同时进行 Insert/Update 的语句 ,也就是说当存在记录时,就更新 (Update),不存在数据时,就插入 (Insert)。
Block-Range Indexes (BRIN)
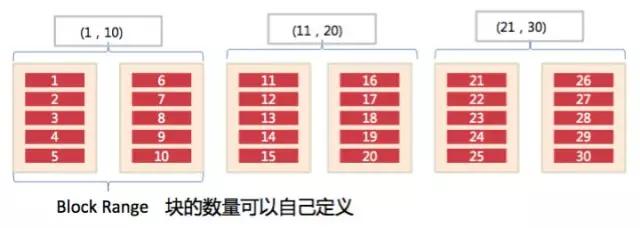
通过以下图例我们可以更好地理解这个新的 Index:
此图感谢李元佳
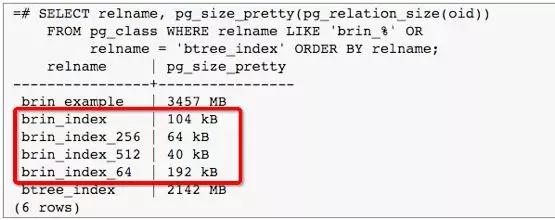
BRIN(Block Range Index):保存数据块的值的摘要信息,如存储某一组块里面所有记录中的最大最小值,与 Exadata 的 Storage Index 相似。 通过 BRIN 我们可以让 Index 大小指数级缩小,当然不恰当的使用也会影响性能,以下是一个 DEMO:

我们可以看到 BRIN 比 Btree 小很多。全表扫描之前,先从范围索引过滤掉不满足条件的数据块,可大大提高全表扫描的性能。这一点对于按顺序排列的表效果尤为明显。以下的 DEMO 将说明 BRIN 对空间的节省情况:
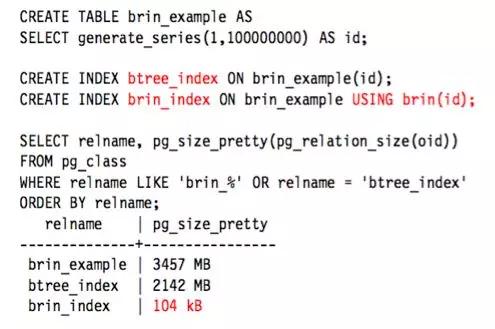

但此时你会发现,系统 SELECT 性能相比 B-Tree 要低不少。

那 BRIN 有什么用处呢?请见以下另一个 DEMO 测试 Insert 性能:
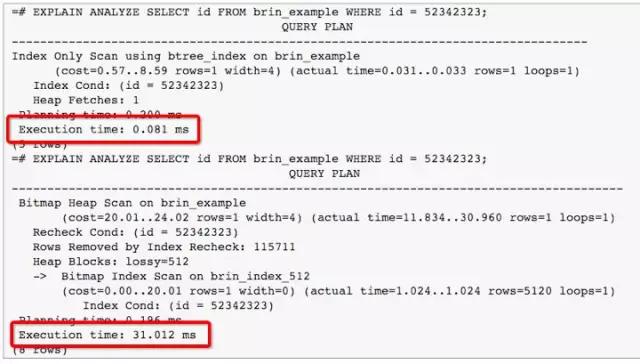
我们可以明确看到,B-Tree 下 Insert 性能比 BRIN 慢了 1 倍,因此对于只要进行少量“等于”或“范围查询”操作,但要求高速数据写入的场景这是十分适用的。如:按日期存放的日志表。
另外方面如同 Oracle Exadata 的 Storage Index,在一个类索引结构中存储一定范围的数据块中某个列的最小和最大值。当查询语句中包含该列的过滤条件时,就会自动忽略那些肯定不包含符合条件的列值的数据块,从而减少 IO 读取量,提升查询速度,当然是会比 btree 慢一些。
OLAP 数据分析操作支持 array_agg, GROUPING SETS, CUBE, and ROLLUP(略过,有用到这些功能的都懂)这是 9.5 的新功能
Row-Level Security (RLS)
如果你是 Oracle 的粉丝,VPD 是不会陌生的。这一功能在“ PCI DSS - 支付卡行业(PCI)数据安全标准”是十分重要的一个实现手段,可以确保任何用户都不会读取到其它用户的信息,所有用户实现最核心的隔离。
在 PostgreSQL 9.5 中我们叫它做 RLS,通过以下操作我们就可以启动 RLS:
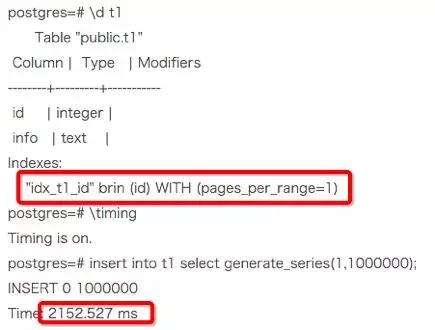
接下来我们可以进行一些测试操作:

我们建立了两个用户,通过“SET SESSION AUTHORIZATION”操作,相当于是用不同的用户进行登陆后再执行 INSERT 操作。

转换为 postgres 超级用户身份后,我们可以看到所有数据,但当前我使用 emp1 和 emp2 用户身份操作时,我们将只能得到当前用户写入的数据。

WAL 日志压缩
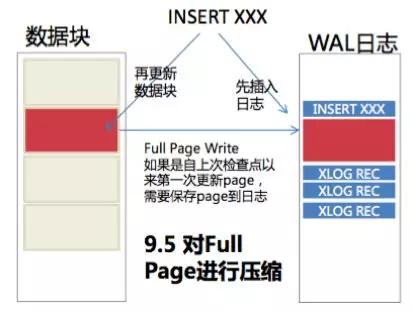
PostgreSQL 以 16MB 为单位保存 WAL 日志文件,由于日志文件会保存数据写入前及写入后的信息,因此在大量 UPDATE 及 DELETE 操作后 WAL 会持续增大。 这将大量占用用户的归档空间,如果用户需要通过网络将WAL存放到远端网络存储或磁带机中,就会导致网络带宽大量备占用。
PostgreSQL 9.5 提供了 WAL 日志压缩功能解决此问题,写日志时候对数据块进行压缩。往磁盘写更少的数据,复制的传输的量也会少,可以更新的性能提高,但 CPU的消耗量会上升。

pg_rewind功能
自 9.0 开始 PostgreSQL 提供流式数据复制功能 Streaming Replication,以实现两个数据库商的数据同步。
但 9.5 版本以前,一旦数据库的 Master 节点出现硬件故障导致系统宕机,在主节点维修完毕想要重新加入到数据库集群时,我们往往需要对此数据库进行重新的全量数据初始化。如果数据量在 100GB 以下恢复时间还是可以接受的,然而一旦数据少为大一点,到达几百 GB 甚至 TB 级别,全量数据初始化将是一个灾难!
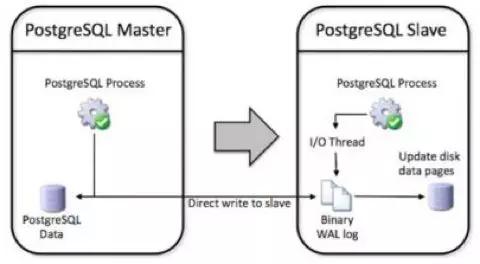
由于 PostgreSQL 基于文件系统进行数据存储,因此我们也可以借助 rsync,但由于 rsync 无法做到 Block 块级别的数据差异复制,时间依然很难达到用户要求。 因此 PostgreSQL 9.5 提供了 pg_rewind,这是一个同步 PostgreSQL 数据目录的工具,其结果等同于用 rsync 同步 data 数据目录。
pg_rewind 的优点是,它用 WAL 来确定更改的数据块,不需要在集群里读取所有文件,当数据库很大时,这样的特性会让它运行起来更快。
JSONB 数据操作增强
PostgreSQL 自从 9.2 开始提供 JSON 的支持,对于哪些只通过 node.js 开发应用系统的同学来说,JSON 数据最佳的数据库当然是 MongoDB。
但是对于传统就使用关系型数据库的企业用户及应用软件开发商而言,SQL 是根本,系统要求严谨的 ACID 关联,开发人员也不习惯使用 SQL 以外语法。 特别是很多系统已经持续开发集成 3 年甚至 5 年,但由于当前需要对接互联网,而再构建一个新的 MongoDB 进行 JSON 数据存储,开发端就显得特别麻烦。
而在 PostgreSQL 中,你可以:
我们可以看到,通过 json_data 表中 data 字段的 name 属性,我们混合 SQL及 JSON 实现了一次数据库内部的跨表 JOIN。
如果你担心性能问题,你还可以在data->>name这个属性上建立GIN索引,操作如下:
但此处要注意,我们使用“?”问号作为数据比对的操作符而不是“=”等号。 在最新的 PostgreSQL 9.5 中增加的多个进行 JSON 数据内部操作的特性:

通过这些特性我们通过 SQL 函数对 JSON 对象内部的属性进行动态的添加及修改,整个操作就如同在 SQL 中操作 Redis 一样,十分方便。
在 PostgreSQL 中使用 JSON 除了可以更好地处理移动互联网数据外,对于传统业务的由于业务形态可能随时变化,而导致数据库中“宽表”设计也有很大的帮助。
在 PostgreSQL 中可以将所有“宽表”的列定义成一个 JSONB 字段即可,未来因应数据操作需求,可以再进行不同属性的索引处理。对于以下多种业务都十分实用:
- 政务系统中资产管理的“卡片”数据
- 医疗行业用户病历管理
- 教育行业中学生考卷管理
- 零售行业中产品资料及标识的管理
PostgresSQL 还可以做什么


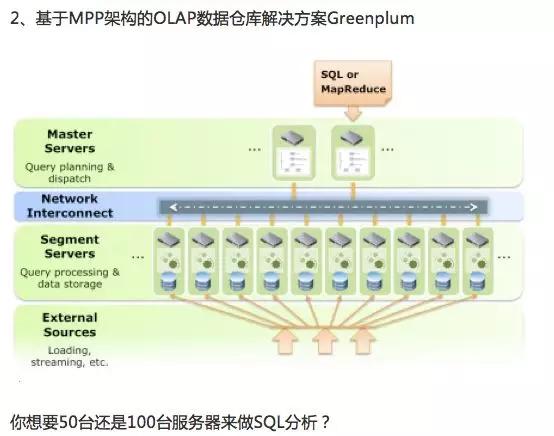
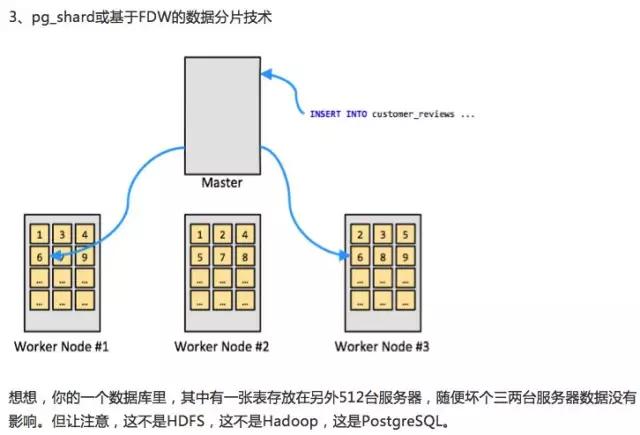
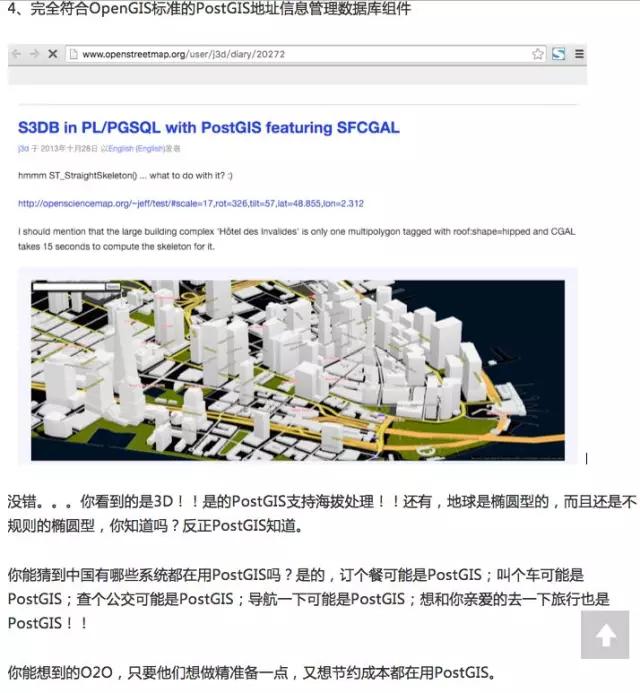
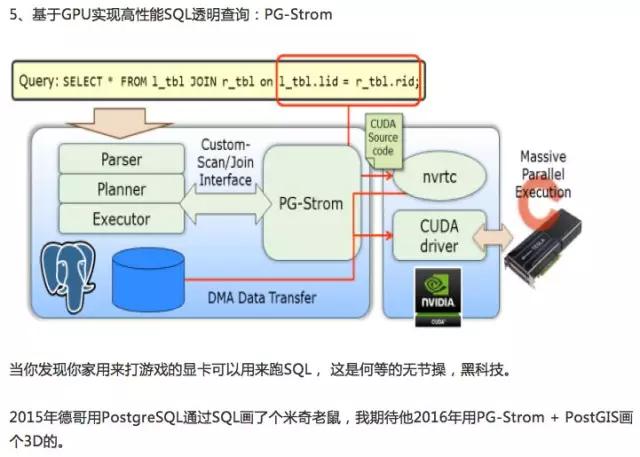
Q & A
- 布道者为什么要用 pg?对比 db2 oracle mysql 有什么优势?
- 布道者为什么用 PG:
- 功能要求(如:JSON、GIS、分析函数、窗口函数)。
- 性能要求(多表 JOIN、复杂事务并发)。
- 基于线程体系稳定性。
- 基于 BSD 协议开放,没有 GPL 的开源限制。
- 已经在此行业看到大量机会。
- 如果以上你就同意,那就是癖好、情结。
MySQL:PG 除地市场差点,PG 会给你更多的功能体验,在复杂系统中大大节省开发人员时间;
Oracle:成本优势,不要告诉我你公司都是正版,在功能不差的前提下 PG 绝对与 Oracle 谐美(除了一点 RAC 在最佳环境下数据库故障 0 中断,PG 用 HA 所以最少要 20 秒);
DB2:只要你给我一小机,PG 也可以 - PG 可以把堆表按照一个索引来组织行?把 Proxy 的路由功能给内置了?
是可以的,关于 Proxy,建议这个问题者直接找我讨论,有好多方案。 - JSONB 跟 MongoDB 的 Bson 差不多?
差别很大,JSONB 基于严格遵循 ACID 的关系型数据库上,可以直接与 SQL 进行互动 - 和 MongoDB 比起来,PostgreSQL 在 JSON 支持方面有什么异同点?能否取代前者,适合什么样子的情景?
不能取代,MongoDB 操作是 find/save,还可以很好地横向扩展,但无法做到严格的数据原子性 ACID。PostgreSQL 的 JSON 更适合传统企业进行移动互联网改造时使用,同时与 SQL 进行直接操作,减少开发量,快速上线新系统。 - PostgreSQL 9.5 新特性有 OLAP 支持,而列存引擎对 OLAP 的性能提升是非常重要的,请问 PostgreSQL9.5 之后的版本会增加原生列存引擎的支持吗?尤其是在 Greenplum 开源之后。
术业有专攻,PG 会做 OLTP 支持 OLAT 操作,GP 会作为数据仓库方案 - PG 的 GIS 跟 MongoDB 的 Geo 是否类似?有啥区别?
地球是椭圆型的,而且还是不规则的椭圆型,在 PostGIS 中可以处理,PG 可以处理更为复杂的 GIS 版本,具体请看 PostGIS 的手册。还有 PG 支持高度,所以可以做 3D。 - 都说 PG 的功能比 Mysql 强大,能否简单说说强大的地方?
这个太多了,可见 http://yq.aliyun.com/articles/2727,这些很多 MySQL 都做不到,PG 是个功能型的数据库,但我不认为谁更强大。如同,我要的是上下班的自行车,你给我个特斯拉,我还要花钱买停车位。但如果你有复杂查询,多表JOIN,那 PG 是你的救星。 - PostgreSQL 在国内有哪些大型案例?
去哪儿网、平安科技、国家电网都在用并在 2015 年大会分享过,很多用 PG 都公司都没有对外公布,希望大家一同 show 出来我们在计划做“ PostgreSQL 黄页”。同时很多国产数据库都基于 PG,真要找大型案例,可能还会有在军、国字头 - pg_shard 算是 postgreSQL 最好的水平扩展方案吗?
这个可不一定要注意 pg_shard 不保证 ACID,水平扩展还有 Greenplum 及 Postgres-XC/XL/X2 - 如果要依赖 postgresql 的 transaction id 增长做增量改变的查询,靠谱吗?比如查询某个 trabsaction id 之后修改过的记录。
这个需要小心,transaction id 是有极限的,通过 vacuum 会回收,可以线下交流一下你想做什么,或许有其它方案。 - 因为服务器时间很难保证误差,所以没有基于时间去查询增量数据,而是基于 pg 的 age 函数去判断 transaction id 的先后,想问下这样的方案可靠不,有没有别人这么用过。
同上,线下讨论,这个话题就大了,我猜你是想做分布式锁管理,而且还想去中心化。 - 以前在 128G 内存的机器上使用过 PG,试验过各种配置参数,但是似乎 PG 都很难充分利用内存,请问这是配置姿势不对,还是 PG 固有的问题?
我们刚刚完成了极限测试:CPU、内存、IO 应该都用到尽头了,当前性能比 O要高一些,正在请 IO 的高手来优化。 - PG 使用的比较多的是游戏和数据分析,PG 在这两个应用场景下有啥优势吗?
首先,并发事务处理方面 PG 天生是有性能优势的,游戏中核心依然是交易系统所以不少都会用 PG。再者在数据分析方面,由于支持“窗口函数”,所以更能快速解决问题,还有就是多表 JOIN 性能也是 PG 会比较高。 - 请问 pg 的运维成本相比 mysql 或 oracle 如何?
如果你的系统不大,PG 比 Oracle 高(因为人少)、Oracle 比 MySQL高(因为工资高)。如果你的系统很庞大,都一样!但是 Oracle 收费! - PostgreSQL 和 OceanBase 在阿里内部的关系?或者说相比 OceanBase,PostgreSQL 的优劣势是什么?
首先,没有直接关系。PostgreSQL 是在阿里云 RDS 中的一个数据库引擎,主要提供云数据库服务。两者没有太大的可比性,OB 有很多创新已经不是传统关系型数据库的模型了。
本文策划邓启明,编辑王杰,审校 Tim Yang,转载请注明来自高可用架构 「ArchNotes」微信公众号。
请在登录后发表评论,否则无法保存。
