| PostgreSQL中的锁 原作者:李浩 创作时间:2016-12-17 19:45:30+08 |
doudou586 发布于2016-12-15 19:45:30
 评论: 3 评论: 3
 浏览: 19396 浏览: 19396
|
PostgreSQL中的锁
作者: 李浩
简介:
本文主要介绍了PostgreSQL内核中的锁及其相应的底层实现原理和使用场景。我们知道在RDBMS中一个影响系统性能的主要因素是锁的使用。通常我们对于锁的认知从不同的维度上看可以分为:(1)从锁的对象种类上看,例如:表锁,行锁等;(2)从锁的访问类型上看,例如:共享锁,独占锁,读锁,写锁等等;(3)实现机制上看,例如:spinlock,LWLock,LOCK等。对于这些分类下各个锁在底层实现的机制上有什么不同,即性能如何。对于这些锁的认识,无论是对于内核人员还是DBA来说都有着非常重要的意义。
1. spinLock(自旋锁)及内存屏障问题.
自旋锁,作为一种高效但却是属于一种”死等”的形式的锁机制,自旋锁通常用在需要高效且锁占用时间较短的场景下。正是由于该锁的机制-“wait-and-loop”形式,当其并未获得资源的情况下,并会不停止状态检测:等待指定满足条件。因此,其会导致大量的CPU指令执行nop指令,导致大量的CPU计算机性能被浪费,且其也不会像其它锁那样在无法获得资源的情况下执行挂起操作,自旋锁将一直处于”wait-and-loop”即所谓的空等状态。
Spinlock原型:
Thread1: Thread2:
while (checkLock()) { while (checkLock()) {
doSomething1(); doSomething2();
}
} 因此从该特性我们可以看出,自旋锁的使用场景了:高效且锁占用时间较短的场景下。从上述的分析可以看出自旋锁将严重的依赖于系统底层所提供的相关指令系统来实现上述的checkLock功能。checkLock函数将检查是否获得某些资源,当获得某项资源后,并将状态修改为已获得状态,从而使得其它线程无法获取到对该资源的访问,即我们通常所说的test-and-set操作。为了高效的实现test-and-set操作,不同的系统平台均在指令层级提供了相应的指令来完成该项操作,从而使得test-and-set能够以高效的硬件来实现,保证了我们的spinlock的高效。但这也带来一个负面影响,spinlock上所附加的其它信息较少,例如:锁的等待队列,资源访问信息等等。
虽然从硬件指令层级提供tas指令为我们实现高效的spinlokc提供了便利,但这会给我们的使用带来极大的问题:为此我们需要知道我们当前系统所运行的相关系统环境是否支持tas或者其所支持的tas是否需要额外信息等等,例如:当前操作系统的类型以及相应的CPU的型号等。下面我们就就来看看在PostgreSQL中是如何来化解易用性和平台无关性之间的矛盾。
PostgreSQL中关于spinlock的描述均被放在spin.h和spin.c中。在spin.h中为硬件(平台)无关spinlock的实现的描述.
我们知道spinlock在底层的实现时候将会严重的依赖tas(test-and-set)指令,在早期cpu不支持该指令的情况下,其采用了一种循环检查的方式来实现,但随着技术的进步慢慢的将这些操作使用更高效的硬件来完成并在指令层级提供了tas指令。这使得我们能够以更加方便的方式来完成spinlock的实现。
上面的讨论我们解决了spinlock在实现中的checkLock的实现问题。下面我们讨论一下spinlock在使用过程中需要注意的问题:对于spinlock所保护的对象,其一般是一个共享对象,例如:一个状态信息,或者缓存中的共享数据。这些信息被不同的线程并发访问,为了能够维护这些共享信息的正确状态,这些对象就是锁进行保护的对象。为了能够及时的获取到这些共享对象的及时状态信息,我们对这些对象使用volatile关键字进行描述。而这也是9.5版本之前我们所使用的解决方式是: 对于spinlock所需要保护的对象及spinlock本身上加volatile关键词。虽然volatile关键词的使用在一定程度上减少了由于线程对于共享数据镜像不一致所导致的问题,但这仍然会存在着问题。
当前为了提高CPU执行效率通常采用乱序执行(Out-of-order Execution)和多发射技术(Multi-Launch)。在乱序执行的状态下,通常会将对于共享对象的读写指令LOAD/STORE进行重排操作,从而使得在某些条件下(多核系统状态下)导致我们对于该对象的访问出现错误。例如:对于如下语句:其中f,x初始值为0,并测试f是否等于0,当f不等于0时候打印该值。
while (f == 0); // Memory fence required here print x;
此时在处理器2之上运行如下代码:
x = 42; // Memory fence required here f = 1;
将x的值设置为42,f的值设置为1,如果在没有乱序执行的状态下,此时对于x的修改将先于对f的修改,此时在处理器1上执行的代码结构将是打印出x的值为42。但是,实际情况并不完全按照上述的剧本执行。由于cpu或者编译器的优化(因为在处理器2上x,f两变量之间无前后的依赖关系,使得我们可以优化将f=1该语句先于x=42执行),将会产生如下的一种情况:
在处理器1上执行完while (f==0);语句后,此时在处理器2上优先执行f=1的语句,这样在进行第二次while(f==0)语句时,由于f已经被设置为1,测试条件不满足,从而输出的结果是x=0,即处理器1上将打印出0.当然还有一种可能是处理器1上对于x值的获取操作在f==0该语句之前执行,从而使得x的值为一未确定值。 为了防止编译器在优化过程中对相关代码优化导致的re-order问题[因为编译器在进行代码优化的过程中会将某些代码视作无用代码进行优化]。我们使用了相应的内存屏障机制来保存我们的代码的LOAD和STORE指令的执行顺序并不会因为被过度优化而导致从新排序的问题。为了解决这些问题提出了:内存屏障的概念。
TAS操作的使用时候,对于某些系统结构上(weak memory ordering 弱内存序化)必须使用硬件层的内存屏障指令来保证,指令的正确的顺序,因为在某些系统架构上(例如:alpha平台上)如果不使用内存屏障将会导致代码的乱序执行,从而获得一个错误的结果。
屏障指令,是一类同步屏障指令,是CPU或编译器在对内存随机访问的操作中的一个同步点,使得此点之前的所有读写操作都执行后才可以开始执行此点之后的操作。大多数现代计算机为了提高性能而采取乱序执行,这使得内存屏障成为必须。 语义上,内存屏障之前的所有写操作都要写入内存;内存屏障之后的读操作都可以获得同步屏障之前的写操作的结果。因此,对于敏感的程序块,写操作之后、读操作之前可以插入内存屏障。
内存屏障是底层原语,是内存排序的一部分,在不同体系结构下变化很大而不适合推广。需要认真研读硬件的手册以确定内存屏障的办法。x86指令集中的内存屏障指令是:lfence (asm), void _mm_lfence (void) 读操作屏障;sfence (asm), void _mm_sfence (void)写操作屏障;mfence (asm), void _mm_mfence (void)读写操作屏障。
1. spinlock实现介绍.
上文中我们提及在spin.xx中描述了平台无关spinlock描述,而在s_lock.h 中定义了硬件相关的spinlock的实现,而spinlock的操作又依赖于tas操作的支持。同时,在不同的系统平台下对于tas的支持又有着不同的方式。在我们对PostgresSQL进行编译的时候,可以通过configure中的enable_spinlocks参数来配置是否使用spinlock当我们使用 -- enable_spinlocks=false的时候表明,在PostgreSQL中将不会使用spinlock,而是使用Semaphore来对其进行模拟,但这会极大的削弱性能,因此除非特定情况下,一般无需对该参数进行设置。
考虑到对于spinlock的实现需要tas操作的支持,因此当检测到当前的系统不支持tas操作的时候,通常系统会建议将spinlock支持关闭,但是这也会带来系统性能的大幅下降。
#ifndef HAS_TEST_AND_SET #error PostgreSQL does not have native spinlock support on this platform. To continue the compilation, rerun configure using -- disable-spinlocks. However, performance will be poor. Please report this to pgsql-bugs@postgresql.org. #endif
在检查测到系统支持tas操作后,Postgres将会依据所在的平台不同进行分别处理;
#ifdef WIN32_ONLY_COMPILER typedef LONG slock_t; #define HAS_TEST_AND_SET #define TAS(lock) (InterlockedCompareExchange(lock, 1, 0)) …
上述描述可看出:windows平台下,TAS操作的实现依赖于compare and exchange操作:InterlockedCompareExchange。而在Unix/Linux平台下,由于对于各平台所提供的compare and exchange实现方式不同因此需要对各种平台进行分门别类的进行处理。具体描述如下:
#if defined(__GNUC__) || defined(__INTEL_COMPILER) //当为gnu c或者intel编译器时
static __inline__ int
tas(volatile slock_t *lock)
{ //由于对于comp and exchange的支持不尽相同,同时为了保持最大的系统效率故而采用asm方式
register slock_t _res = 1;
__asm__ __volatile__(
" cmpb $0,%1 \n"
" jne 1f \n"
" lock \n"
" xchgb %0,%1 \n"
"1: \n"
: "+q"(_res), "+m"(*lock)
:
: "memory", "cc");
return (int) _res;
}
#else
static __inline__ int
tas(volatile slock_t *lock)
{
int ret;
ret = _InterlockedExchange(lock,1); /* this is a xchg asm macro */
return ret;
}
#endif
又如我们在arm或者__aarch64__系统平台下:
#if defined(__arm__) || defined(__arm) || defined(__aarch64__) || defined(__aarch64)
#ifdef HAVE_GCC__SYNC_INT32_TAS
#define HAS_TEST_AND_SET
#define TAS(lock) tas(lock)
typedef int slock_t;
static __inline__ int
tas(volatile slock_t *lock)
{
return __sync_lock_test_and_set(lock, 1);
}
对于其它平台上的实现在这里就不在详细给出,具体实现还请各个读者参考s_lock.h中所给出的具体实现描述。这里我们对于spinlock的底层实现机制做一个总结:compare and exchange作为核心其承担了TAS操作的功能,当系统平台中支持已经存在支持COMPARE AND EXCHANGE操作时候,我们将依据不同的平台环境来给出TAS的定义。
至此,我们已经在硬件层上封装了一个spinloc锁实现所需的原始函数[硬件依赖],但是为了方便用户使用我们在其上面进行在封装,以便用户可以方便使用,其便是 spin.h 和spin.c 存在的原因。 在spin.h中我们定义了如下的四类宏:
#define SpinLockInit(lock) S_INIT_LOCK(lock) #define SpinLockAcquire(lock) S_LOCK(lock) #define SpinLockRelease(lock) S_UNLOCK(lock) #define SpinLockFree(lock) S_LOCK_FREE(lock)
我们很容易从字面上可以看出,SpinLockInit对一个锁对象进行初始化操作,SpinLockAcquire获取一个锁对象,SpinLockRelease释放一个已经获得的锁对象,SpinLockFree释放相应的锁对象。下面我们就简单来分析一下spinlock的加锁操作,S_LOCK(lock)。
int s_lock(volatile slock_t *lock, const char *file, int line, const char *func)
{
SpinDelayStatus delayStatus;
init_spin_delay(&delayStatus, file, line, func);
while (TAS_SPIN(lock))
{
perform_spin_delay(&delayStatus);
}
finish_spin_delay(&delayStatus);
return delayStatus.delays;
}
从上述分析我们知道spinlock的核心是一个wait-and-loop操作,当检查到锁被占用时,将处于等待状态;当在获得锁资源后,首先是将锁的状态设置为占用状态,从而阻止其它线程对于该锁的访问,这些操作由TAS_SPIN来完成。又从TAS_SPIN的定义可以看出其实质是一个TAS操作,而这也是我们上述花费大量篇幅来讨论TAS操作的原因。
对于spinlock的semaphore实现版本这里我们就不做讨论了,有兴趣的读者自行分析吧。这里我们还需额外的提及一点:slock_t类型,从compare and exchange操作中我们可以看出,slock_t依据不同的平台被定义为long,unsigned int,unsigned char等等类型。
2. spinLock使用场景分析.
下面我们讨论对于spinlock的使用场景,spinlock属于轻量级的锁,适用于对某个share object操作较多,并且占用时间不长的情景下使用,即我们在较小的代码中使用,对于复杂场景下的使用我们一般不采用spinlock,而采取其他方式。实例代码如下:
void ParallelWorkerReportLastRecEnd(XLogRecPtr last_xlog_end)
{
FixedParallelState *fps = MyFixedParallelState;
Assert(fps != NULL);
SpinLockAcquire(&fps->mutex);
if (fps->last_xlog_end < last_xlog_end)
fps->last_xlog_end = last_xlog_end;
SpinLockRelease(&fps->mutex);
}
从上述的使用可以看出,spinlock所包含的临界区通常较小,通常为数行代码范围内,正是由于spinlock的特点要求我们在临界区内进行快进快出的操作;相反,如果临界区属于一大段具有复杂逻辑关系的代码则不适合使用spinlock进行。首先,大段临界区代码需要执行较长的时间,而spinlock又属于wait-and-loop方式,从而使得大量的CPU处于空转状态严重消耗资源;再者,在一大段逻辑复杂的临界区内当执行发生异常程序流程跳转后,不容易确定spinlock释放的正确位置,容易造成死锁。而spinlock又不存在死锁检查机制来消除死锁。因此,我们需要一种能够解决上述问题的一种新的锁。幸好,Postgres提供了轻量锁(Light Weight Lock)-LWLock;
3. LWLock原理分析.
LigthWeight Lock我们称为轻量锁,其主要是以互斥访问的方式用来保护共享内存数据结构,下面是Postgres对于LWLock的说明,从中我们可以清楚的看到该种类型的锁的目的和作用以及执行保护的方式。其提供两种锁访问方式:共享锁和独享锁。其相应的代码分别在:storage/lmgr/lwlock.xxx文件中。 与spinlock相比较而言,LWLock又是基于什么样的机制来实现的呢? 在早期的LwLock实现过程中使用了spinlock 作为其底层实现。我们可以从其相应如下的数据结构可以看出。在早期的版本中:LWLock使用一个链表( PGPROC *head ,PGPROC *tail )来保存那些正在争取访问锁而暂时无法得到满足的进程,我们称之为 Waiting List;同时,使用shared来描述先在共同持有该共享锁的进程数,LWlock在所有已知的平台下其大小在16-32个字节。
typedef struct LWLock
{
slock_t mutex; /* Protects LWLock and queue of PGPROCs */
char exclusive; /* # of exclusive holders (0 or 1) */
…
} LWLock;
但在最新的版本中,我们可以其已经将spinlock从LWLock的定义中移除,去而代之是一个uint32类型的状态-state。与spinlock的机制相似我们通过对该state对象的操作来实现高效的锁机制,可以说其实质也是由spinlock来支持的。相应的waiting list也将链表形式由直接通过指针访问方式改为通过进程编号在PGPROC进程链表中获取链表节点的方式来获取是哪个进程处于等待锁的状态。
除了上述的独享和共享模式之外,LWLock也可以用来执行对某个变量满足特定条件的等待操作,LWLockWaitForVar。
typedef struct LWLock
{
uint16 tranche; /* tranche ID */
pg_atomic_uint32 state; /* state of exclusive/nonexclusive lockers */
proclist_head waiters; /* list of waiting PGPROCs */
#ifdef LOCK_DEBUG
pg_atomic_uint32 nwaiters; /* number of waiters */
struct PGPROC *owner; /* last exclusive owner of the lock */
#endif
} LWLock;
为了系统在访问LWLock时的速度,我们通常将LWLock的大小限制为2的幂保证每个LWLock对象不会跨越cache line边界,因而可以降低了cache竞争; 在9.4版本之前,每个LWLock将会保存在一个单独的数组中并存放于主共享内存中(Main Shared Memory),但在最新的版本中我们还可以将LWLock保存动态共享内存段中(Dynamic Shared Segment,DSM),最后形成一个含有32槽(Lock Tranches)的锁槽,LWLockTranche。其中有:main,buffer_mapping,lock_manager,predicate_lock_mangaer等。
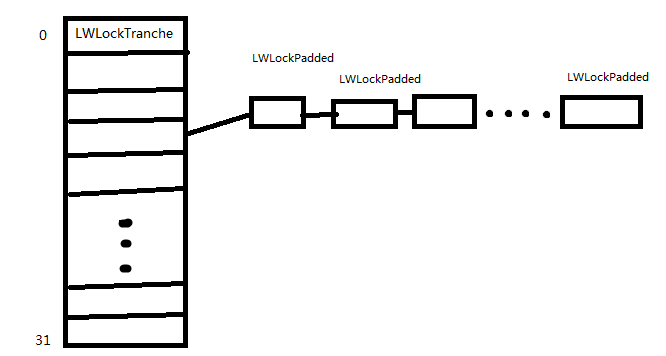
图-:LWLock Tranches示意图
在函数 void CreateLWLocks(void)中,系统将对Lwlock对象进行分配相应的内存空间并分配其到相应的LWLockTranche中。 具体操作如下:
void CreateLWLocks (void)
{
if (!IsUnderPostmaster) {
...
/* Initialize all LWLocks */
InitializeLWLocks();
}
/* Register all LWLock tranches */
RegisterLWLockTranches();
}
其中由IntializeLWLocks来创建各个LWLockTranche中的锁。其中内建的tranches共有Main,buffer mapping共18个,其各个槽相应的ID由 枚举类型BuiltinTrancheIds进行描述。
在main槽中我们一共初始化 43,对于其中各个LWLock对象所起的作用可以参考 lwlocknames.h中所给出的描述。由于这些轻量锁在系统初始化时候已经创建,因此我们可以使用形如LWLockAcquire(CLogControlLock, LW_EXCLUSIVE);这样的语句来访问这些锁对象;buffer mapping中共有128个LWLock对象;而在Lock Manager与PredicateLock每个中各有16个 LWLock。
在讨论完基本的操作后,我们将讨论LWLock的获取问题。在早期版本中系统通过lockid来获取该编号的锁的访问权限。例如:void LWLockAcquire(LWLockId lockid, LWLockMode mode),但在最新的版本中我们不在使用该种方式,而是直接操作LWLock对象,bool LWLockAcquire(LWLock *lock, LWLockMode mode)。函数LWLockAcquire的核心是通过检查锁对象中的state状态来判定是否能够获得对该锁的访问权限,LWLockAttemptLock。当我们在该函数内检查到锁的状态发生变化时,则将该锁的状态设置为我们所需要的状态并通知调用者该锁的占用状态。当我们申请独占锁的时候同时记录下该锁的持有者,而这些操作均在LWLockAttemptLock内完成。
static bool LWLockAttemptLock(LWLock *lock, LWLockMode mode)
{
AssertArg(mode == LW_EXCLUSIVE || mode == LW_SHARED);
/*
* Read once outside the loop, later iterations will get the newer value
* via compare & exchange.
*/
old_state = pg_atomic_read_u32(&lock->state);//获取锁的旧状态
/* loop until we've determined whether we could acquire the lock or not */
while (true)//循环检查锁的状态
{
…
desired_state = old_state;
if (mode == LW_EXCLUSIVE)
{
lock_free = (old_state & LW_LOCK_MASK) == 0;
if (lock_free)
desired_state += LW_VAL_EXCLUSIVE;
}
else
{
lock_free = (old_state & LW_VAL_EXCLUSIVE) == 0;
if (lock_free)
desired_state += LW_VAL_SHARED;
}
// pg_atomic_compare_exchange_u32其封装了compare and exchage操作,同时避免了内存乱序问题
if (pg_atomic_compare_exchange_u32(&lock->state,
&old_state, desired_state))
{
if (lock_free) {
return false;
}else
return true; /* someobdy else has the lock */
}
}
pg_unreachable();
}
在完成LWLockAcquire的核心功能后,在LWLockAcquire函数中我们只有进行不断的尝试:(1)当本次尝试能够获取到该锁资源时,跳出尝试操作并将该锁的持有者添加到 held_lwlocks数组中;(2)当该锁资源在本次尝试中并未获取到,此时执行等待操作,值得该锁的持有进程释放对于该锁的持有。此时将唤醒这些尝试操作,值得获取到对该锁的访问权限。LWLockAcquire中的代码描述了上述等待及唤醒操作。
LWLockReportWaitStart(lock);
TRACE_POSTGRESQL_LWLOCK_WAIT_START(T_NAME(lock), T_ID(lock), mode);
for (;;){
PGSemaphoreLock(&proc->sem);
if (!proc->lwWaiting)
break;
extraWaits++;
}
/* Retrying, allow LWLockRelease to release waiters again. */
pg_atomic_fetch_or_u32(&lock->state, LW_FLAG_RELEASE_OK);
TRACE_POSTGRESQL_LWLOCK_WAIT_DONE(T_NAME(lock), T_ID(lock), mode);
LWLockReportWaitEnd();
在完成了LWlock的申请所有情况后,下面分析下锁的释放(Lock Release)。在锁的持有者执行LWLockRelease函数的调用后,将释放对该锁的持有。LWLockRelease函数的原型为: void LWLockRelease(LWLockId lockid) 其中lockid为所持有锁的ID。根据我们上述的加锁的分析我们可以大致得出:(1)将其从持有者数组中删除;(2)更新lock对象的态信息;(3)唤醒其等待队列上的等待进程。下面我们就给出LWLockRelease函数的实现介绍。
void LWLockRelease(LWLock *lock)
{
….
//(1)从持有数组中删除
for (i = num_held_lwlocks; --i >= 0;)
{
if (lock == held_lwlocks[i].lock)
{
mode = held_lwlocks[i].mode;
break;
}
}
...
//(2)更改其状态信息
if (mode == LW_EXCLUSIVE)
oldstate = pg_atomic_sub_fetch_u32(&lock->state, LW_VAL_EXCLUSIVE);
else
oldstate = pg_atomic_sub_fetch_u32(&lock->state, LW_VAL_SHARED);
...
//(3)唤醒等待进程
if (check_waiters)
{
/* XXX: remove before commit? */
LOG_LWDEBUG("LWLockRelease", lock, "releasing waiters");
LWLockWakeup(lock);
}
...
}
至此,我们已经完成了对LWLock的主要操作:Acquire和Release的分析。从上述文章中的分析可以看出,对于LWLock对象其实现的核心思想与spinlock相近,但相比起spinlock其包含了更多信息:例如:该锁的持有者,锁的等待队列等。我们可以通过对所的持有者分析,判定是否存在着导致死锁的循环等待条件。
LWLock可以称之为内核对象锁,因为我们可以发现其加锁的对象通常是类似于:SyncScan,BtreeVacuum等内核系统对象。其封锁的范围相对于spinlock来说范围进一步扩大,适用于临界区较大且具有复杂的逻辑处理流程。
4. LWLock使用场景分析.
int BackendXidGetPid(TransactionId xid)
{
ProcArrayStruct *arrayP = procArray;
….
if (xid == InvalidTransactionId) /* never match invalid xid */
return 0;
LWLockAcquire(ProcArrayLock, LW_SHARED);
for (index = 0; index < arrayP->numProcs; index++)
{
int pgprocno = arrayP->pgprocnos[index];
volatile PGPROC *proc = &allProcs[pgprocno];
volatile PGXACT *pgxact = &allPgXact[pgprocno];
…
}
LWLockRelease(ProcArrayLock);
return result;
}
从上面可以看出:相比较与spinlock而言,LWLock其保护的临界区返回较大,而在临界区内可以存在着较为复杂的逻辑关系,LWLock临界区内由于其存在着一定复杂度其执行时间相对较长,对于效率要求相对不高且执行频次相对较少的场景下。 那么是否存在着在适用于对象或者操作一级锁呢?因为通常在某些操作过程中其具有较长的操作时间,例如:对于SELECT…FOR UPDATE操作或者是对于对于Page的操作,或者对于Tuple的操作?
5. LOCK原理分析.
相比起spiinlock和LWLock,LOCK/LOCALLOCK可以称之为一个重量级的锁。通常该锁在数据库级的对象上进行加锁操作,例如:我们需要对于对一个表或是一个page进行加锁操作的话。
我们还注意到一点,无论是在spinlock还是在LWLock中,系统均不会对其相关的操作进行日志记录并将其该操作日志发送到备机上,但对于LOCK操作系统会将相关操作进行日志记录并将其发送到备机上,这点我们可以在LOCK申请阶段处理函数LockAcquireExtended中得到验证。
if (log_lock)
{
LogAccessExclusiveLock(locktag->locktag_field1,
locktag->locktag_field2);
}
因此,我们可以看出其与之前锁的区别,可以这么说:LOCK是属于操作一级的锁,其更加面向于高层描述。数据库中所涉及到的高层操作:例如:数据修改,事务操作等等。lock.h中的LockTagType中就给出了相应的分类描述,例如:LOCKTAG_RELATION描述了加锁对象是整个Relation表;同样LOCKTAG_TUPLE则描述了当我们需要对于某个Tuple进行操作之前,通过该标识来获取对Tuple的加锁操作。 这些标识其实质是用来进行LOCK hash table查找时所使用的标识。为什么这么说呢?因为,在Postgres创建每个backend时候,Postgres均会为该backend创建
一个名为 “LOCK hash”的hash 表和一个名为“PROCLOCK hash”的hash表,同样一个名为“LOCALLOCK hash”的hash表也被创建。前两者是属于shared类型,而后者则是属于non-shared类型。每一个hash表项中或保存LOCK对象,或者是PROCLOCK或者LOCALLOCK。而这些所保存的对象描述于我们所申请的锁的相关信息,例如:该锁被持有的次数,该锁的访问模式等等。
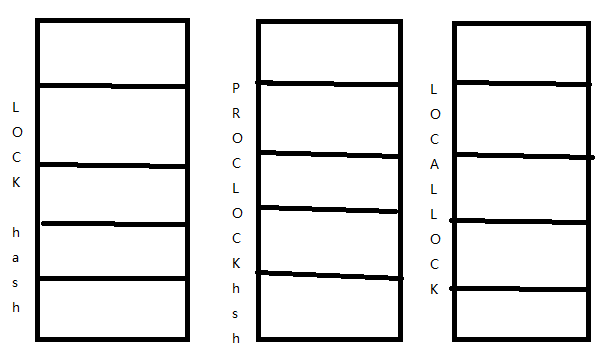
图二:LOCK hash table示意图
那么,为什么会有shared和non-shared类型之分呢?这是由于Postgres的进程型架构所决定的,因为PostgresMain会在执行过程中fork出数个进程,有些资源子进程是可以继承父进程,但这并不能够完全满足我们的需求。例如:需要所有的进程都可以访问的资源,而这也是shared类型对象存在的依据。同样,在Postgres中还存在着其它类型的共享对象。例如:我们在并行执行过程中需要不同的worker访问某些共享资源,这也是在最新版本中对于共享内存部分的代码进行大量修改并添加对于动态共享内存支持的原因。Postgres采用内存映射文件来实现进程间的通信功能。这点多线程架构下不同,还请读者仔细体会其中的差别。 当InitLocks函数完成上述关于LOCK相关信息的初始化后我们便可以通过相关的函数来说获取相应的锁信息。对于系统中的LockMethodData以及PROCLOCK等数据类型在这里就在做详细讨论,请自行分析。
下面我们看看LOCK锁的申请,LockAcquire。从Postgres所给出的说明该函数会完成锁的冲突检查;当检查到我们加锁对象上存在着访问冲突时候,则会进行休眠;当未检查到对象上存在着访问冲突时候,则会将该对象设置正确的访问模式。Postgres提供了如下几种访问模式:(1)AcessSharedLock,例如:当我们进行select操作时候,我们可以将select所操作的对象设置为AcessSharedLock模式;(2)RowSharedLock,例如:SELECT…FOR UPDATE/FOR SHARED操作;(3)RowExclusiveLock,例如:执行INSERT/UPDATE/DELETE操作时;(4)SharedUpdateExclusiveLock,例如:执行VACUUM,ANALYZE,CREATE INDEX CONCURRENTLY操作时;(5)ShareLock,例如:CREATE INDEX;(6)ShareRowExclusiveLock,例如:Exclusive模式;(6)ExclusiveLock,例如:执行块更新操作时候;(7)AcessExclusiveLock,例如:在执行ALTER TABLE,DROP TABLE,VACUUM FULL,LOCK TABLE操作时。
在LockAcquire中,(1)会依据LOCKTAG中所给定的需要加锁对象的相关信息进行hash表查找。因为同一锁可能被持有多次,为了加快访问速度,故而将这些所缓存在hash table中。例如:当我们需要执行对表进行加锁操作时候,会将我们所需要操作的数据库变化,表的编号等信息设置在LOCKTAG中;当我们需要执行对Tuple进行加锁操作时候,会将数据库编号,表的编号,块号及相应的偏移量等信息设置在LOCKTAG中。SET_LOCKTAG_XXX完成了对于相应LOCKTAG的设置工作;
(2)查找LOCALLOCK hash表并依据查找结果进行相应处理;
locallock = (LOCALLOCK *) hash_search(LockMethodLocalHash, (void *) &localtag, HASH_ENTER, &found);
(3)检查该对象是否已经获相应的锁;例如:当已经获得该类型的锁时候,
if (locallock->nLocks > 0) //该锁已经被持有
{
GrantLockLocal(locallock, owner); //更新锁持有者等信息
return LOCKACQUIRE_ALREADY_HELD;
}
(4)依据相应条件,对该锁申请操作添加WAL日志;(5)进行冲突检查(6)当不存在相应的访问冲突后,则进行锁申请操作并记录下该资源对于锁的使用情况;在检查冲突的过程时,当发现存在着访问冲突后,如果需要进行等待操作时候,则使用WaitOnLock进行等待;
partitionLock = LockHashPartitionLock(hashcode); LWLockAcquire(partitionLock, LW_EXCLUSIVE); //此时成功获得对该对象的加锁访问。 //依据LOCKTAG查询或插入新LOCK对象到LOCALLOCK表 proclock = SetupLockInTable(lockMethodTable, MyProc, locktag, hashcode, lockmode); …. GrantLock(lock, proclock, lockmode); //更新锁的状态 GrantLockLocal(locallock, owner);
(7)告知锁的申请结果。
从上述的讨论可以看出,与spinlock以及LWLock不同,LOCK是通过查询LOCALLOCK hash表以及PROCLOCK hash表来判定该对象上的加锁情况,PROLOCK中的holdMask就描述了当前所持有锁的访问类型;同时,由于在锁的申请和释放过程中,系统会记录相应锁的持有者信息,该锁上等待进行的信息等,因此该类型的锁的死锁检测成为可能,DeadLockCheck函数完成了上述所说的死锁检测功能,而这也是spinlock所不具备的一项重要功能。对于LockRelease这里就不在进行详细分析了。
6. LOCK使用场景分析.
void LockRelation(Relation relation, LOCKMODE lockmode)
{
…
SET_LOCKTAG_RELATION(tag,
relation->rd_lockInfo.lockRelId.dbId,
relation->rd_lockInfo.lockRelId.relId);
res = LockAcquire(&tag, lockmode, false, false);
if (res != LOCKACQUIRE_ALREADY_HELD)
AcceptInvalidationMessages();
}
Oid index_create(…) {
….
LockRelation(indexRelation, AccessExclusiveLock);
….
}
与之类似,LockPage,LockTuple,LockDatabaseObject等函数均满足了我们在对于特定对象的加锁操作,而这也是我们通常所所说的表锁,行锁的概念。
7. 小结.
本文主要讨论了Postgres中存在的锁的实现机制以及各种类型锁的使用场景和各种的优缺点。 Spinlock作为粒度最小,效率最高的锁,其通常使用在临界区较小且临界区执行时间较短而又对效率要求较高的场景下。Spinlock并不适应于较大其具有复杂逻辑关系的临界区的场景,此时如果使用spinlock将会导致整个系统效率急速下降;同时,spinlock并不会提供死锁检查和死锁消除功能,并不会提供等待队列,锁的持有者等信息。
LWLock,轻量锁。与spinlock不同,LWLock由于其对于临界区的要求并不像spinlock一样,因此其使用的场景较为宽泛,同时LWLock提供了等待队列以及锁的持有者信息,使得我们可以追踪LWLock的使用情况从而使得构建死锁检查和消除功能成为可能; LOCK,重量级锁。其锁包含的对象通常是较大范围,例如:一整张表,一个页面,一个事务操作等等。相对应与LWLock仅有的Shared和Exclusive模式,LOCK提供了更多的访问模式,一般使用在较高的逻辑层级之上。

请在登录后发表评论,否则无法保存。
